这篇文章由我十月中旬在 LeanCloud 和十月末在 Node Patry 杭州 进行的技术分享整理而来。
Atom 是 GitHub 在 2014 年发布的一款基于 Web 技术构建的文本编辑器,我从 2014 年末开始使用 Atom 完成我的全部工作,对 Atom 很是喜爱,也创建了 Atom 的中文社区、翻译了一部分 Atom 的文档和博客。今天我将着重介绍 Atom 背后的故事,包括底层的 Electron、如何对 Atom 进行定制、Atom 的插件化机制、Atom 在启动速度和渲染性能方面的优化等。
GitHub 的联合创始人之一 Chris Wanstrath 自 2008 年便有一个想法,希望使用 Web 技术构建一个像 Emacs 一样赋予开发者充分定制的能力的编辑器。但当时他忙于他的主要工作 —— GitHub,所以 Atom 一度被搁置,直到 2011 年,GitHub 添加了一个使用 Ace 实现的在线编辑代码的功能,这重新点燃了 Chris Wanstrath 对 Atom 的热情,于是他开始在业余时间开发 Atom。在 2011 年末,Atom 成为了 GitHub 的正式项目,也有了一些全职的同事加入,最后在 2014 年初 Atom 正式发布了,并于 2015 年发布了 1.0 版本。
所以 Atom 有什么亮点呢,我总结了这样几点:
- 像 Sublime Text 一样开箱即用
- 像 Emacs 一样允许开发者充分地定制
- 基于 JavaScript 和 Web 技术构建
- 开源且拥有一个活跃的社区
虽然 Sublime Text 之类的编辑器已经足够好用了,第一天学习编程的新手也可以快速上手,但它们仅提供了非常有限的拓展性;而在另外一个极端,像 Vim 和 Emacs 这样的编辑器虽然赋予了开发者充分定制的能力,但却有着陡峭的学习曲线。虽然 Atom 的初衷可能并非如此,但 Atom 的确做到了兼顾易用性和可拓展性,在这两种极端中间找到了一个平衡。
就像 Java 开发者会使用基于 Java 构建的 Eclipse 或 IntelliJ IDEA、Clojure 开发者会使用基于 Lisp 的 Emacs 一样,作为 JavaScript 开发者我们也需要一款基于 JavaScript 和 Web 技术构建的编辑器。我觉得用自己熟悉的语言和技术去改造工具,并从工具的实现中得到启发这是很重要的一点,就像我后面介绍的那样,作为 Web 或 Node.js 开发者,我们都可以从了解 Atom 的设计和实现中受益。
Vim 和 Emacs 之所以能在过去几十年始终保持活力,很大程度上是因为只有「开源」才能构建一个持久的、具有生命力的社区。GitHub 当然也意识到了这一点,所以 Atom 同样是开源的,并且它现在已经有了一个活跃的社区。
Electron
Atom 是基于 Electron,这是一个帮助开发者使用 Web 技术构建跨平台的桌面应用的工具,实际上 Electron 原本叫 Atom Shell,是专门为 Atom 设计的,后来才成为了一个独立的项目。Electron 将 Chromium 和 Node.js 结合到了一起:Chromium 提供了渲染页面和响应用户交互的能力,而 Node.js 提供了访问本地文件系统和网络的能力,也可以使用 NPM 上的几十万个第三方包。在此基础之上,Electron 还提供了 Mac、Windows、Linux 三个平台上的一些原生 API,例如全局快捷键、文件选择框、托盘图标和通知、剪贴板、菜单栏等等。
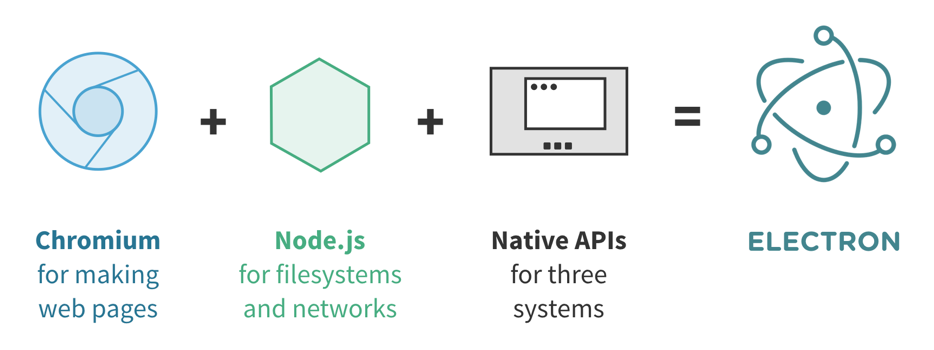
基于 Electron 的应用往往会有很大的体积,即使在打包压缩之后通常也有 40MiB,这是因为 Electron 捆绑了整个 Chromium 和 Node.js。但这也意味着你的应用运行在一个十分确定的环境下 —— 你总是可以使用最新版本 Chromium 和 Node.js 中的特性而不必顾及兼容性,这些新的特性往往会有更好的性能同时提高你的开发效率。
我们来试着用 Electron 编写一个简单的 Hello World:
const {app, BrowserWindow} = require('electron')
let mainWindow
app.on('ready', function() {
mainWindow = new BrowserWindow({width: 800, height: 600})
mainWindow.loadURL(`file://${__dirname}/index.html`)
})
其中的 index.html:
<body>
<h1>Hello World!</h1>
We are using node <script>document.write(process.versions.node)</script>,
Chrome <script>document.write(process.versions.chrome)</script>,
and Electron <script>document.write(process.versions.electron)</script>.
</body>
可以看到,我们就像在使用 NPM 上一个普通的包一样在使用 Electron 来控制 Chromium 来创建窗口、加载页面,你也可以控制 Chromium 来进行截图、管理 Cookie 和 Session 等操作;同时在页面中我们也可以使用 process.versions 这样的 Node.js API,最后我们的 Hello World 看起来是这样的:
我们都知道 Chromium 使用了一种多进程的架构,当你在使用 Chromium 浏览网页时,你所打开的每一个标签页和插件都对应着一个操作系统中的进程。在 Electron 中也沿用了这样的架构,Electron 程序的入口点是一个 JavaScript 文件,这个文件将会被运行在一个只有 Node.js 环境的主线程中:
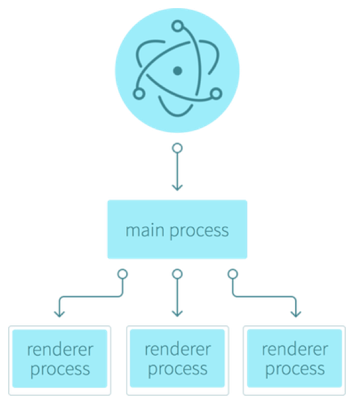
由主进程创建出的每个窗口(页面)都在一个独立的进程(被称作渲染进程)中运行,有着自己的事件循环,和其他窗口互相隔离,渲染进程中同时有 Chromium 和 Node.js 环境,其中 Node.js 的事件循环被整合到了 Chromium 提供的 V8 中,两个环境间可以无缝地、无额外开销地相互调用。
而主进程的主要工作就是管理渲染进程,同时还负责调用 GUI 相关的原生 API(例如托盘图标),这是通常是来自操作系统的限制。渲染进程如果需要调用这些 API,或者渲染进程之间需要通讯也都需要通过和主进程之间的 IPC(进程间通讯)来实现,Electron 也提供了几个用于简化 IPC 的模块(ipcMain、ipcRenderer、remote),但今天我们就不详细介绍了。
目前已经有非常多基于 Electron 的应用了,下面是一些我目前正在使用的应用,借助于 Electron,这些应用大部分都是跨平台的:

- VS Code 是微软的一款文本编辑器,也可以说是 Atom 的主要竞争产品。
- Slack 是一款即时通讯软件。
- Postman 是一个 HTTP API 调试工具。
- Hyper 是一个终端仿真器。
- Nylas N1 是一个邮件客户端。
- GitKraken 是一个 Git 的 GUI 客户端。
- Medis 是一个 Redis 的 GUI 客户端。
- Mongotron 是一个 MongoDB 的 GUI 客户端。
定制 Atom
对 Electron 的介绍就到此为止了,毕竟今天的主角是 Atom。作为 JavaScript 开发者,当我们听说 Atom 是基于 Web 技术构建起来的,相信大家的第一个反应就是打开 Chromium 的 Developer Tools:
可以看到,整个 Atom 都是一个网页 —— 文本编辑区域也是通过大量的 DOM 模拟出来的。我们点开 Atom 的主菜单,可以看到几个简单的自定义入口:

Config 对应 ~/.atom/config.cson 是 Atom 的主配置文件。Init Script 对应 ~/.atom/init.coffee 其中的代码会在 Atom 启动时被执行。Keymap 对应 ~/.atom/keymap.cson 用来定义按键映射。Snippets 对应 ~/.atom/snippets.cson 可以定义一些代码补全片段。Stylesheet 对应 ~/.atom/styles.less 可以通过 CSS 修改 Atom 的样式。
Atom 最初是用 CoffeeScript 编写的,这是一个编译到 JavaScript 的语言,在当时弥补了 JavaScript 语言设计上的一些不足。但随着后来 ES2015 标准和 Babel 这样的预编译器的出现,CoffeeScript 的优势少了许多,因此 Atom 最近也开始逐步从 CoffeeScript 切换到了 Babel,但后文还是可能会出现一些 CoffeeScript 的代码。
我们可以在 Stylesheet 中先尝试用 Less —— 一种编译到 CSS 的语言来修改一下 Atom 的外观:
// To style other content in the text editor's shadow DOM,
// use the ::shadow expression
atom-text-editor::shadow .cursor {
border-color: red;
}
我们用 atom-text-editor::shadow .cursor 这个选择器指定了 Atom 的文本编辑区域中的光标,然后将边框颜色设置为了红色,保存后你马上就可以看到光标变成了红色:
我们也可以在 Init Script 中编写代码来给 Atom 添加功能。考虑这样一个需求,在写 Markdown 的时候我们经常需要添加一些链接,而链接通常是我们从浏览器上复制到剪贴板里的,如果有个命令可以把剪贴板中的链接自动添加到光标所选的文字上就好了:
atom.commands.add('atom-text-editor', 'markdown:paste-as-link', () => {
let selection = atom.workspace.getActiveTextEditor().getLastSelection()
let clipboardText = atom.clipboard.read()
selection.insertText(`[${selection.getText()}](${clipboardText})`)
})
在这段代码中,我们用 atom.commands.add 向 Atom 的文本编辑区域添加了一个名为 markdown:paste-as-link 的命令。我们先从当前激活的文本编辑区域(getActiveTextEditor)中获取当前选中的文字(getLastSelection),然后使用 Markdown 的语法将剪贴板中的链接插入到当前的位置:
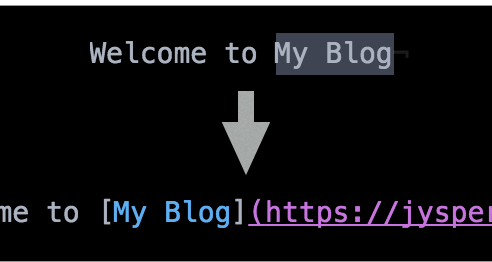
那我们如何执行这个命令呢,虽然 Atom 也提供了一个类似 Sublime Text 的命令面板:
但在实际使用中,我们通常会通过快捷键来触发命令,我们可以在 Keymap 中为这个命令映射一个快捷键:
'atom-workspace':
'ctrl-l': 'markdown:paste-as-link'
'ctrl-m ctrl-l': 'markdown:paste-as-link'
我们可以使用 ctrl-l 这样的快捷键,也可以使用 ctrl-m ctrl-l 这种 Emacs 风格的快捷键。
插件化架构
"packageDependencies": {
"atom-dark-syntax": "0.28.0",
"atom-dark-ui": "0.53.0",
// themes ...
"about": "1.7.2",
"archive-view": "0.62.0",
"autocomplete-atom-api": "0.10.0",
"autocomplete-css": "0.14.1",
"autocomplete-html": "0.7.2",
"autocomplete-plus": "2.33.1",
"autocomplete-snippets": "1.11.0",
"autoflow": "0.27.0",
"autosave": "0.23.2",
"background-tips": "0.26.1",
"bookmarks": "0.43.2",
"bracket-matcher": "0.82.2",
"command-palette": "0.39.1",
"deprecation-cop": "0.55.1",
"dev-live-reload": "0.47.0",
"encoding-selector": "0.22.0",
// ...
}
当我们打开 Atom 核心的 package.json 时,你可以看到 Atom 默认捆绑了多达 77 个插件来实现各种基础功能。没错,Atom 的核心是一个仅有不足两万行代码的骨架,任何「有意义」的功能都被以插件的形式实现。Atom 作为一个通用的编辑器,不太可能面面俱到地考虑各种需求,索性不如通过彻底的插件化来适应各种不同类型的开发任务。
实际上在 Atom 中插件被称为「Package(包)」,而不是「Plugin(插件)」或「Extension(拓展)」,但下文我们还会继续使用「插件」这个词。
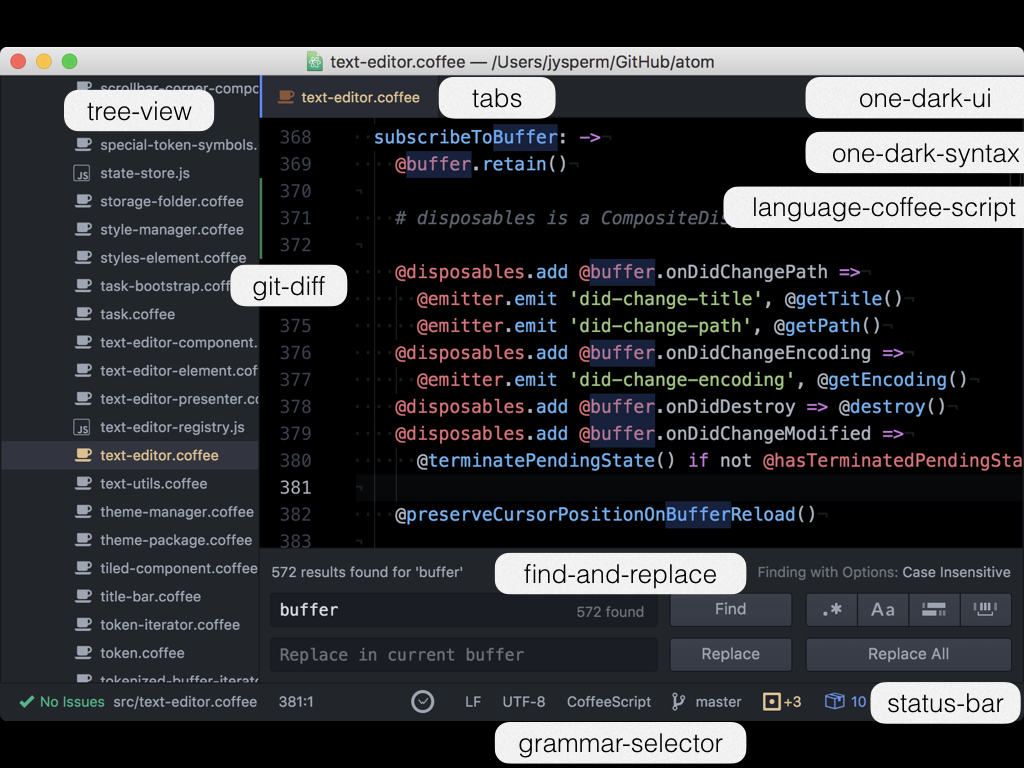
在这张图中我标出了一些内建的插件:
- tree-view 实现了左侧的目录和文件树。
- tabs 实现了上方的文件切换选项卡。
- git-diff 实现了行号左侧用来表示文件修改状态的彩条。
- find-and-replace 实现了查找和替换的功能。
- status-bar 实现了下方的状态栏。
- grammar-selector 实现了状态栏上的语言切换器。
- one-dark-ui 实现了一个暗色调的编辑器主题。
- one-dark-syntax 实现了一个暗色调的语法高亮主题。
- language-coffee-script 实现了对 CoffeeScipt 的语法高亮方案。
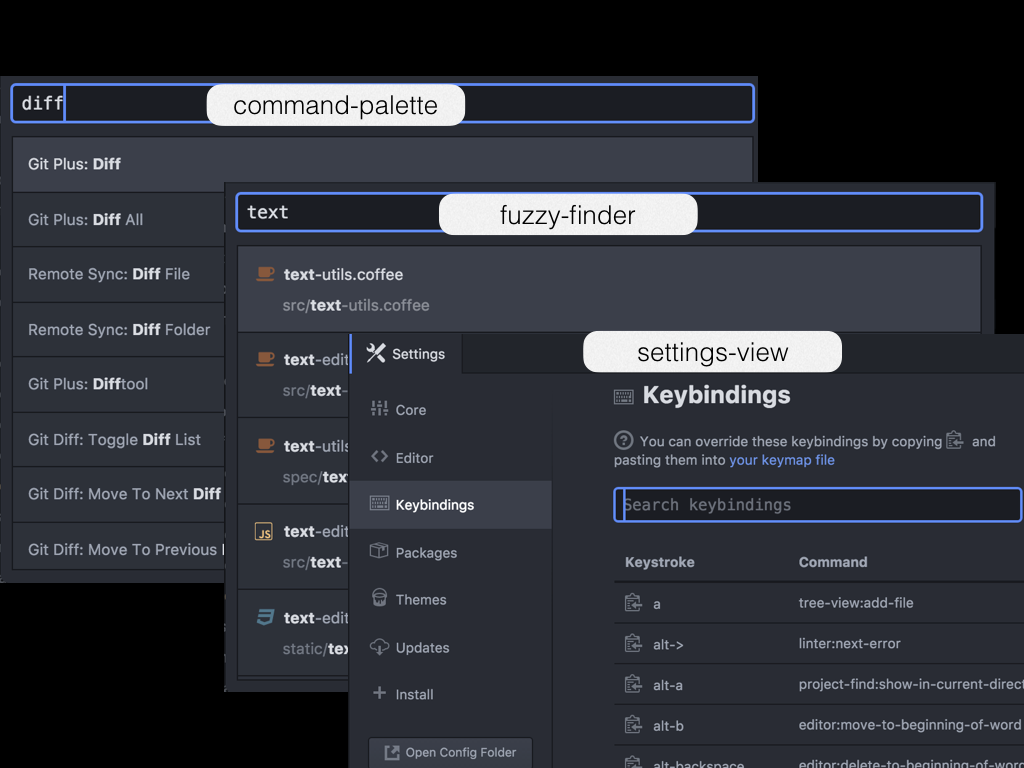
- command-palette 实现了一个命令的模糊搜索器。
- fuzzy-finder 实现了一个文件的模糊搜索器。
- settings-view 实现了一个 Atom 的设置界面。
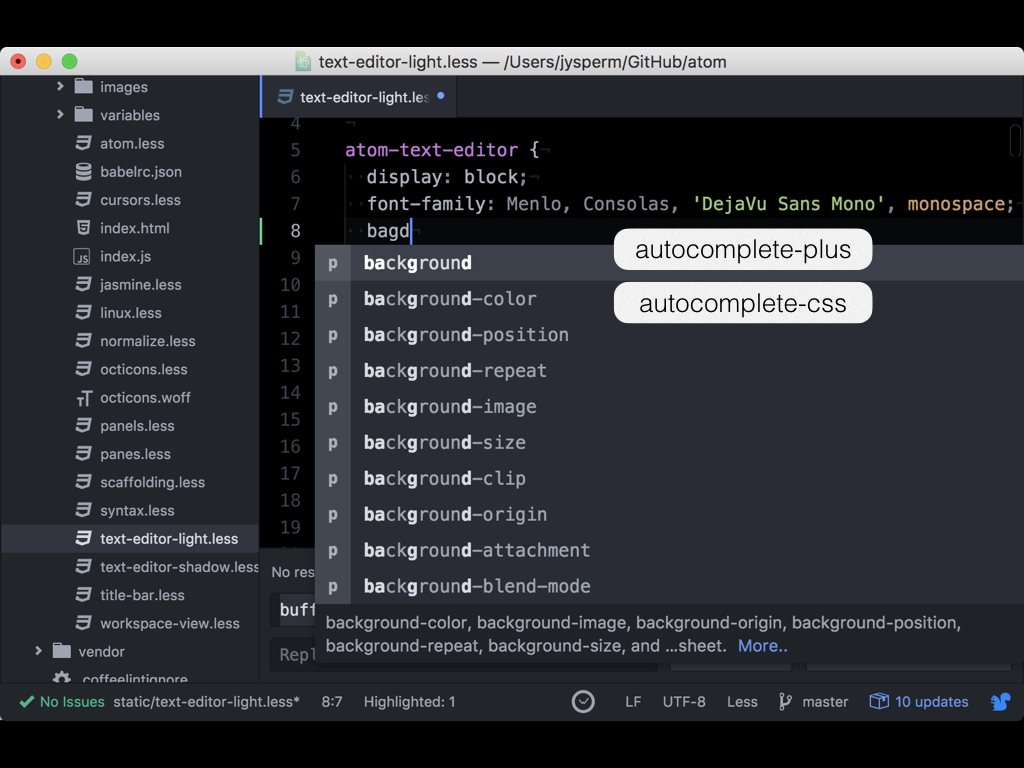
- autocomplete-plus 实现了一个代码补全的列表。
- autocomplete-css 实现了针对 CSS 的代码补全建议。
这么多基础的功能都是以插件的方式实现的,这意味着第三方开发者在编写插件时所使用的 API 和这些内建的插件是完全相同的。而不像其他一些并非完全插件化的编辑器,第三方的插件很难得到与内建功能同样的 API,会受到并不完整的 API 的限制。
这也意味着如果一个内建的功能不够好,社区可以开发出新的插件去替换掉内建的插件。你可能会觉得这样的情况不太可能发生,但其实 Atom 的代码补全插件就是一个例子,Atom 一开始内建的代码补全插件叫 autocomplete,功能较为简陋,于是社区中出现了一个具有更强拓展性的 autocomplete-plus,受到了大家的好评,最后替换掉了之前的 autocomplete,成为了内建插件。
Atom 的插件之间是可以互相交互的,例如 grammar-selector 等很多插件都会调用状态栏的 API,来在状态栏上添加按钮或展示信息:

作为插件当然是可以独立地进行更新的,而一旦更新就会不可避免地引入不兼容的 API 修改,如果 grammar-selector 依赖了一个较旧版本的 status-bar 的 API,而在之后 status-bar 更新了,并且引入了不兼容的 API 调整,那么 grammar-selector 对 status-bar 的调用就会失败。
在 Node.js 中对于依赖版本的解决方案大家都很清楚 —— 每个包明确地声明自己的依赖的版本,然后为每个包的每个版本单独安装一次,保证每个包都可以引用到自己想要的版本的依赖。但在 Atom 里这样是行不通的,因为你的窗口上只有一个状态栏,而不可能同时存在一个 0.58.0 版本的 status-bar 和一个 1.1.0 版本的 status-bar。
因此 Atom 提供了一个服务(Service)API,将被调用方抽象为服务的提供者,而将调用方抽象为服务的消费者,插件可以声明自己同时提供一个服务的几个版本,通过 Semantic Versioning(语义化版本号)表示,例如 status-bar 的 package.json 中有:
"providedServices": {
"status-bar": {
"description": "A container for indicators at the bottom of the workspace",
"versions": {
"1.1.0": "provideStatusBar",
"0.58.0": "legacyProvideStatusBar"
}
}
}
status-bar 同时提供了 status-bar 这项服务的两个版本 —— 0.58.0 和 1.1.0,分别对应 provideStatusBar 和 legacyProvideStatusBar 这两个函数。
而 grammar-selector 的 package.json 中有:
"consumedServices": {
"status-bar": {
"versions": {
"^1.0.0": "consumeStatusBar"
}
}
}
grammar-selector 声明自己依赖 1.0.0 版本以上的 status-bar 服务。Atom 会在这中间按照 Semantic Versioning 做一个匹配,最后选择 status-bar 提供的 1.1.1 版本,调用 status-bar 的 provideStatusBar 函数,然后将结果传入 grammar-selector 的 consumeStatusBar 函数。
通过服务 API,Atom 插件之间的交互被简化了 —— 一个插件不需要关心谁来消费自己的服务、消费哪个版本,也不需要关心谁来提供自己需要消费的服务,保证了插件能够独立地、平滑地进行版本更新和 API 的迭代,也允许实现了相同服务的插件相互替代;如果用户没有安装能够提供对应版本的服务的插件,那么就什么都不会发生。
正因如此,Atom 的很多插件甚至有了自己的小社区,例如 linter 插件提供了展示语法风格建议的功能,但针对具体语言和工具的只是则是由单独的插件来完成的:
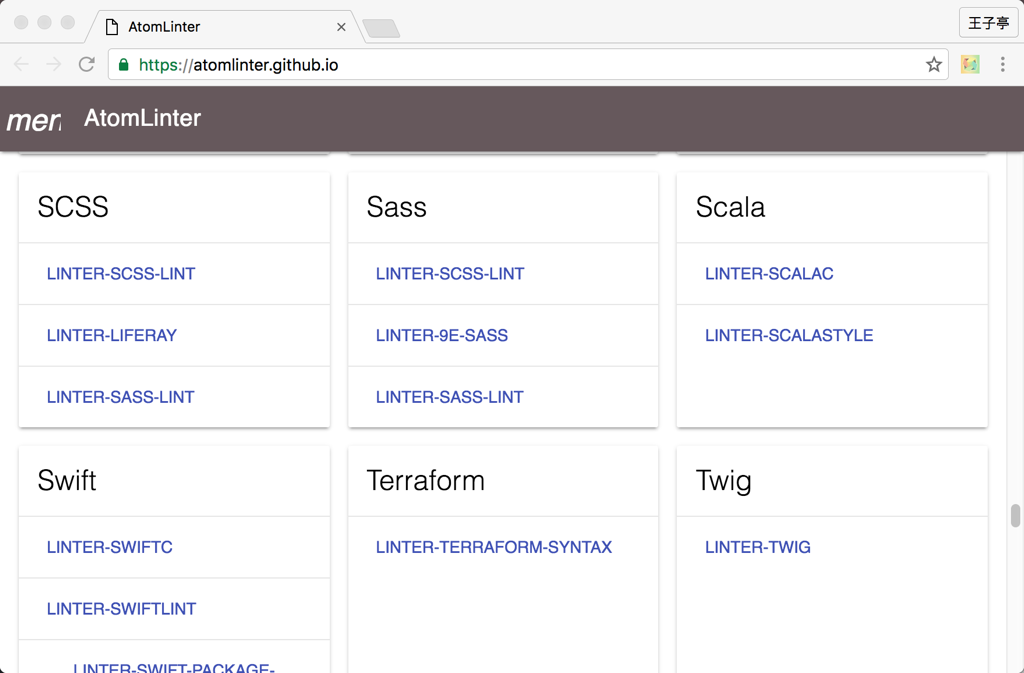
对于这样一个严重依赖插件的社区,插件质量的参差不齐也是一个严重的问题,在 Atom 中,如果一个插件抛出了异常,就会出现下面这样的提示:
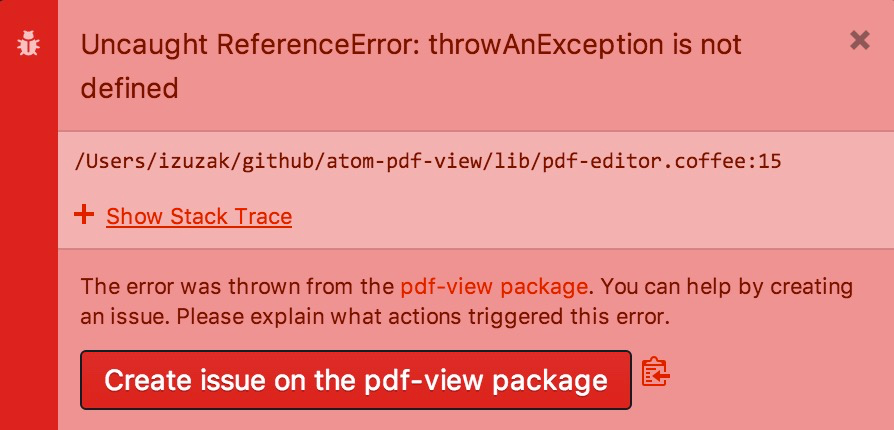
如果你点击创建「Create issue」的话,会自动在插件的仓库上创建一个包含调用栈、Atom 和操作系统版本、插件列表及版本、配置项、发生异常前的动作的 Issue,帮助作者重现和修复异常;如果已经有其他人提交过了这个异常,按钮便会变成「View issue」,你可以到其他人提交的 Issue 中附和一下。
插件化 API
这一节我们将会介绍 Atom 是如何提供给插件定制的能力的,Atom 首先提供了很多全局的实例来管理特定对象的注册和查询,我们通常也称这种设计为「注册局模式(Registry Pattern)」,包括:
atom.commands 管理编辑器中的命令。atom.grammars 管理对语言的支持。atom.views 管理状态数据(Model)和用户界面之间的映射。atom.keymaps 管理快捷键映射。atom.packages 管理插件。atom.deserializers 管理状态数据的序列化和反序列化。
例如我们前面的 Markdown 粘贴链接的例子中:
atom.commands.add('atom-text-editor', 'markdown:paste-as-link', someAction)
我们通过 atom.commands 注册了一个叫 markdown:paste-as-link 的命令并关联到一个函数上;随后其他插件(例如 command-palette)会从 atom.commands 中检索并执行这个命令:
let target = atom.views.getView(atom.workspace.getActiveTextEditor())
atom.commands.dispatch(target, 'markdown:paste-as-link')
从上面的代码中我们可以看到,atom.commands.dispatch 在执行一个命令时还需要指定一个 DOM 元素,结合前面注册命令和映射快捷键的例子,我们可以发现 Atom 中的快捷键和命令实际上都是被注册到一个 CSS 选择器上的。这是因为在 Atom 这样一个复杂的环境中,一个快捷键可能会被多次映射到不同的命令,例如下图,我在存在代码补全的选单的情况下按了一下 Tab 键:
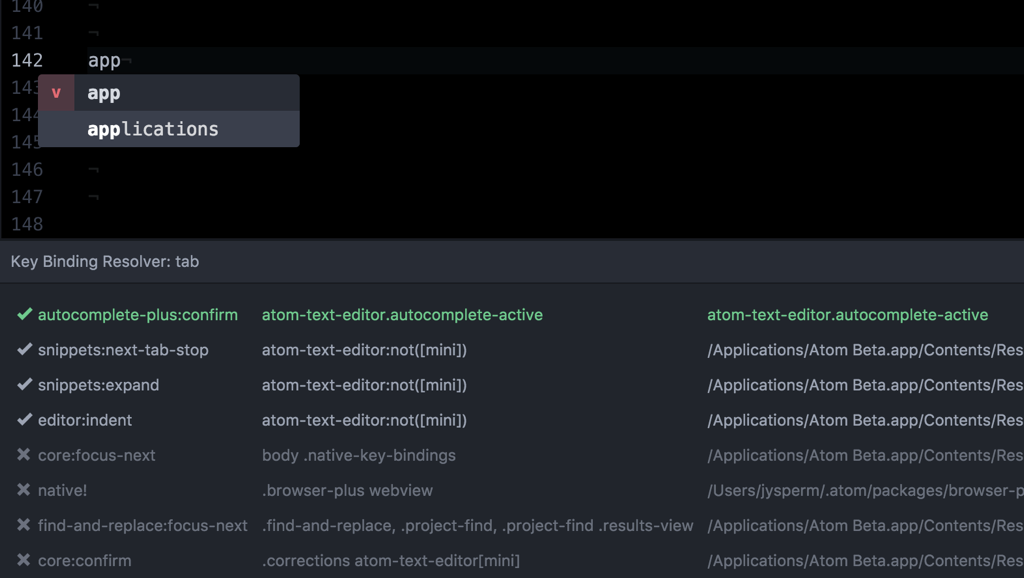
Atom 内建的按键映射调试插件(keybinding-resolver)告诉我们 Tab 键被同时映射到了 8 个命令上,每个映射都有一个相关联的 CSS 选择器(上图中间一列)作为约束。Atom 会从当前焦点所在的元素,逐级冒泡,直到找到一个离焦点最近的按键映射,在上面的例子中,因为当前焦点在代码补全的选单上,所以 Tab 键最后被匹配到了 autocomplete-plus:confirm 这个命令;而如果当前没有代码补全的选单,Tab 键则会被映射到 editor:indent。
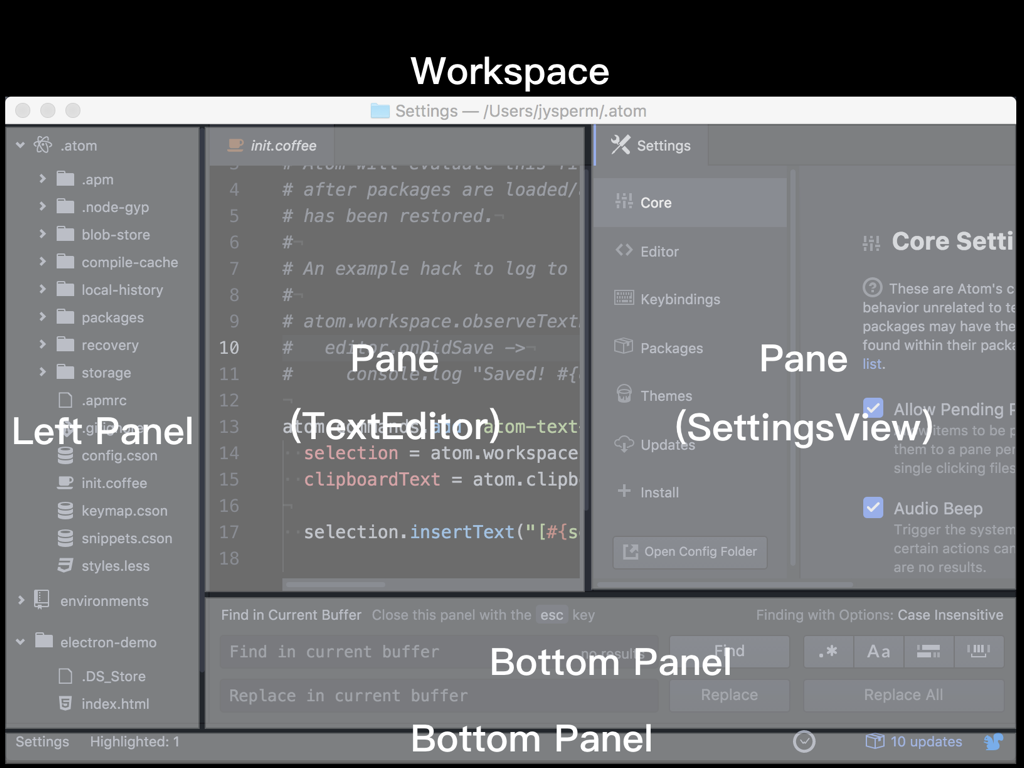
我为 Atom 主界面中的各个可视组件画了一个示意图,Atom 中最核心的区域叫「窗格(Pane)」,窗格可以横向或纵向被切分为多个窗格,窗格中可以是自定义的 DOM 元素(例如右侧的设置界面),也可以是 TextEditor(当然其实这也是一个 DOM 元素)。在窗格构成的核心区域之外,插件可以从四个方向添加「面板(Panel)」来提供一些次要的功能,面板中包含的也是自定义的 DOM 元素。可以想象,上图中的那样一个界面,是在两个窗格的基础上,先从底部添加一个 find-and-replace 的面板,然后从左侧添加一个 tree-view 的面板,最后再从底部添加一个 status-bar 的面板。
Workspace 对应着 Atom 的一个窗口,TextEdtior 对应着窗格中的一个文本编辑区域,可以算是 Atom 较为核心的组件了,我们来看看它们的 API 文档:

Workspace(工作区)和 TextEditor(文本编辑器)算是 Atom 的核心部分。从上图中可以看到,Workspace 和 TextEditor 上首先提供了大量的事件订阅函数(图中仅列出了很少一部分),让插件可以感知到用户在 Workspace 在 TextEditor 中进行的操作,例如 TextEditor 的 onDidChange 会在每次用户修改文本时进行回调;然后也提供了大量的函数让插件可以操作 TextEditor 中的文本,例如 getSelectedText 可以获取到用户当前选择的文本。
事件,或者说「订阅者模式(Publish–subscribe pattern)」,在 Node.js 开发中我们也经常用到,但和 Node.js 的 EventEmitter 略有不同,Atom 提供的 Emitter 提供了更方便地退订事件的功能,所有事件订阅函数都会返回一个 Disposable,用于退订这个事件订阅。例如在 Atom 中,大部分插件的结构是这样的:
class SomePackage {
activate() {
this.disposable = workspace.observeTextEditors( () => {
console.log('found a TextEditor')
})
}
deactivate() {
this.disposable.dispose()
}
}
activate 会在插件被加载时调用,这个插件为当前和未来的每个 TextEditor 注册一个回调,并将返回的 Disposable 保存在一个实例变量上;deactivate 会在插件被禁用时调用,在这里我们调用了之前的 Disposable 的 dispose 方法来退订之前的事件。如果插件的每个事件订阅都这样实现,那么 Atom 便可以在不重启的情况下安装、卸载、更新插件,实际上绝大部分插件也是这样做的。
除此之外,Atom 还提供了很多其他的 API,但在此就不详细介绍了:
atom.config、atom.clipboard、atom.project 提供了对配置项、剪贴板、通知的管理。Color、Selection、File、GitRepository 提供了对颜色、文本选择、文件、Git 仓库的抽象。
这也是我选择了 Atom 而不是它的主要竟品 —— VS Code 的原因:Atom 始终都将可定制性放在第一位,从一开始就是核心仅仅提供 API,而将大部分功能交由插件实现,插件和内建功能使用的是同样的 API,从 1.0 之后几乎没添加过新功能,我觉得这是一个非常优雅的设计;VS Code 还是 Visual Studio 的路线,提供一个对用户而言好用的、高性能的 IDE,后来才出现插件机制,而且很多功能都在核心中,有时第三方插件不能够得到和内建功能一样的对待。
优化启动速度
因为 Atom 插件化的架构,默认就捆绑了 77 个插件,大多数用户在实际使用时都会有超过一百个插件,加载这些插件就花费了启动阶段的大部分时间,让人觉得 Atom 启动缓慢。
Atom 也做了很多尝试来优化启动速度,首先比如延迟加载插件,对于像我们前面提到的为 Markdown 粘贴链接这样功能单一的插件,可以在 package.json 中声明自己提供的功能:
{
"name": "markdown-link",
"activationCommands": {
"atom-text-editor": "markdown:paste-as-link"
}
}
这样 Atom 便可以延迟对这个插件的完整加载,只记录这个插件所提供的命令,markdown:paste-as-link 也会出现在命令面板中,但只有当这个命令第一次被用到的时候,Atom 才会完整地加载这个插件。
显然这个特性非常依赖于插件的作者,如果插件没有在 package.json 中做这样的声明,Atom 就不知道它提供了怎样的功能,也就不得不在启动时完整地加载这个插件。为此,Atom 默认捆绑了一个 timecop 插件,可以记录并展示启动阶段的耗时:
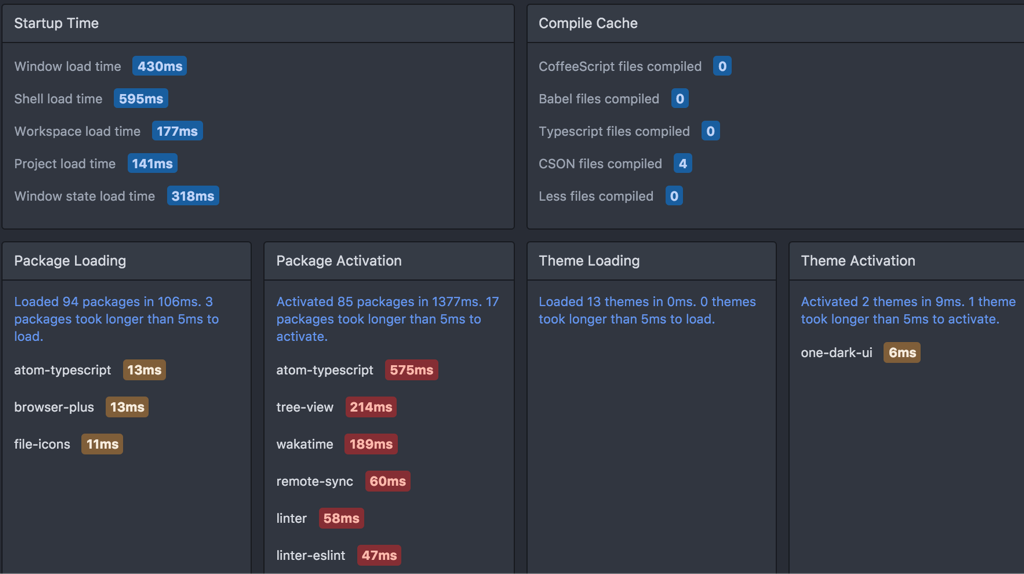
Atom 非常善于通过「社会化」的方式维护社区,因为有了 timecop,终端用户也可以感知到导致启动缓慢的插件,并在 GitHub 上向作者反馈(Atom 要求所有插件的源代码必须托管在 GitHub)。在 Atom 1.0 发布时,有一些 API 的行为有调整,Atom 也是通过类似的方式向终端用户展示未迁移到最新的 API 的插件,督促作者来进行修改。
作为 Node.js 开发者我们都知道 node_modules 中有着大量的小文件,读取这些小文件要比读取单个大文件慢得多,尤其对于非固态硬盘而言。我做了一个简单的统计,Atom 的代码目录(包括 node_modules)中有着 12068 个文件,这些文件的读取显然需要花费启动阶段的很多时间:
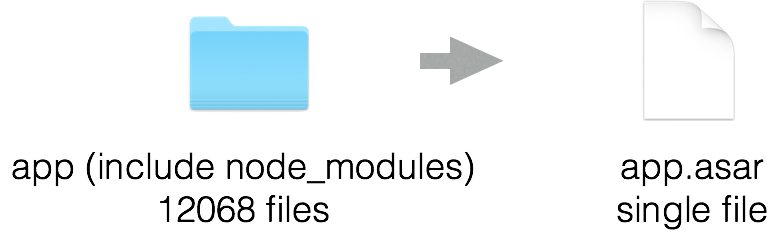
于是 Atom 借助 Electron 提供的 ASAR 归档格式,将整个 node_modules 和其他的代码文件打包成了一个单个的文件,这样 Atom 在启动时只需要读取这一个文件,省下了很多的时间。
优化渲染性能
在 Atom 的早期版本中,当你打开一个代码量较大的文件时,文本编辑区域就会出现卡顿。前面我们提到,Atom 的整个窗口其实就是一个网页,如果网页渲染速度达不到 60fps —— 也就是无法总是在 16 毫秒内完成一次渲染,就会出现人可以感受到的卡顿。所以我们下面介绍的渲染性能优化思路其实是适用于所有的 Web 应用的,只是很少有应用能够有着 Atom 这样复杂的页面。
在网页渲染的过程主要分为「重排(Reflow)」和「重绘(Repaint)」,重排就是重新计算页面中各元素的位置,重绘则是将元素在指定的位置绘制出来。这其中重排是绝大部分卡顿的原因,因为在一个复杂的页面中可能有几万甚至几十万个元素,它们的位置有着复杂的依赖关系,难以并行地进行计算。
众所周知 JavaScript 是基于事件循环单线程地运行的,每当事件循环中的一个函数执行完成,如果它修改了 DOM,浏览器就会尝试进行重排和重绘来更新页面的显示,如果我们将对 DOM 的修改分散在事件循环中的多个函数中,就会多次触发不必要的重排和重绘,所以优化渲染性能有两个关键的思路:
- 避免直接地、频繁地、反复地操作 DOM
- 保持 DOM 树尽可能地小
为了将对 DOM 的操作集中到一起,我们有必要引入一个抽象层,也就是所谓的 Virtual DOM,我们总是在 Virtual DOM 上进行修改,而后再由 Virtual DOM 将我们的多次修改合并,一起更新到真正的 DOM 上。Atom 一开始使用了 React 所提供的 Virtual DOM,不过后来为了更细粒度的控制,切换到了一个自行实现的 Virtual DOM 上:
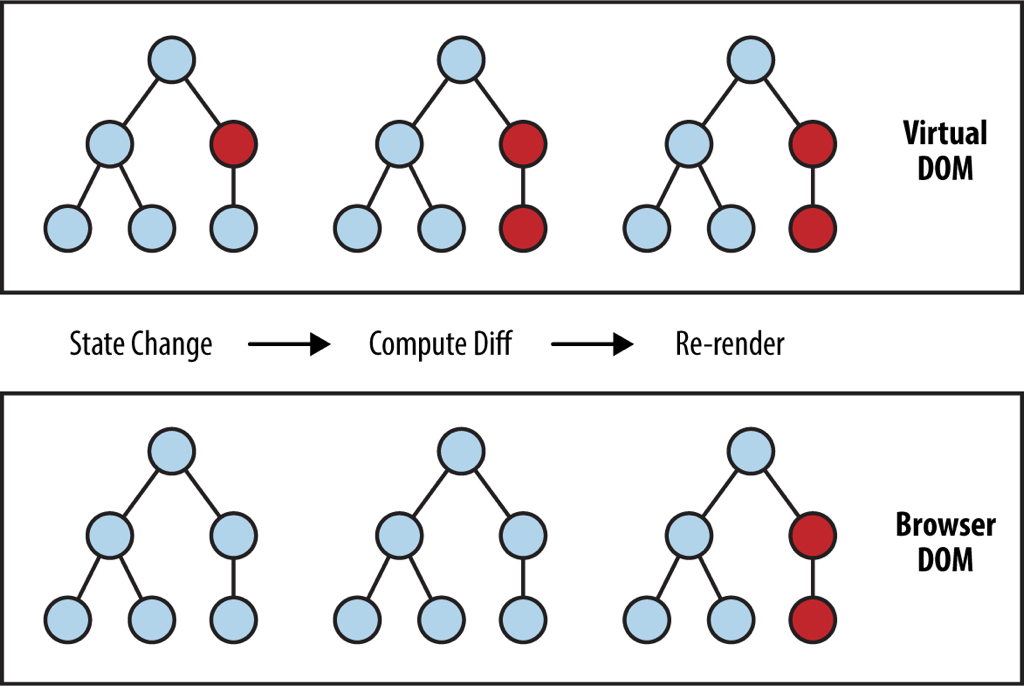
在采用了 Virtual DOM 之后也意味着插件不能够直接操作 Atom 的文本编辑区域的 DOM 了,为此 Atom 提供了 Marker 和 Decoration 这两个机制来允许插件间接地与文本编辑区域交互,Marker 和 Decoration 相当于是对 Virtual DOM 的进一步封装:
Marker 是对一段文本的动态封装,所谓动态是说它并不是单纯地记录「行号」和「列数」,而是即使周围的文本被编辑,Marker 也可以维持在正确的位置,Atom 中文本编辑区域的很多功能都是基于 Marker 实现的,例如光标、选区、高亮、行号左侧 git-diff 的提示、行号右侧 linter 的提示等。
Marker 只是对一段文本的表示,而 Decoration 用来向 Marker 上添加自定义的样式即 CSS 的 class,以便插件通过样式表在编辑区域展示信息:
let range = editor.getSelectedBufferRange()
// invalidate: never, surround, overlap, inside, touch
let marker = editor.markBufferRange(range, {invalidate: 'overlap'})
// type: line, line-number, highlight, overlay, gutter, block
editor.decorateMarker(marker, {type: 'highlight'}, {class: 'highlight-selected'})
在这段代码中,我们先从当前选择的文本创建了一个 Marker,invalidate 属性代表了它如何追踪对这段文本的修改;然后我们向这个 Marker 上创建了一个 Decoration,向这个 Marker 所表示的文本区域添加一个叫 highlight-selected 的 CSS class,type 属性代表了这个 CSS class 被添加到什么位置。
随后我们便可以添加一个样式表,为我们的 CSS class 添加样式:
.highlights {
.highlight-selected .region {
border-radius: 3px;
box-sizing: border-box;
background-color: transparent;
border-width: 1px;
border-style: solid;
}
// ...
}
Atom 通过 Marker 和 Decoration 这样高层次的抽象,避免了插件直接去操作最关键的性能瓶颈 —— 文本编辑区域的 DOM,避免了插件反复修改 DOM 引起的重排。
在之前版本的 Atom 中,当你打开一个大文件时,整个文件都会被渲染成 DOM 作为一个大的页面,供你在 Atom 的窗口中滚动地浏览文件。显然这样会额外渲染非常多的 DOM 元素,也不符合我们前面提到的「保持 DOM 尽可能小」的思路,导致 Atom 无法打开大文件。
因此 Atom 现在会将文本编辑区域的每若干行划分为一个块(Tile),仅去渲染可见的块,而不是渲染整个文件。当用户滚动编辑区域时,新的块会被绘制,不可见的块会被销毁:
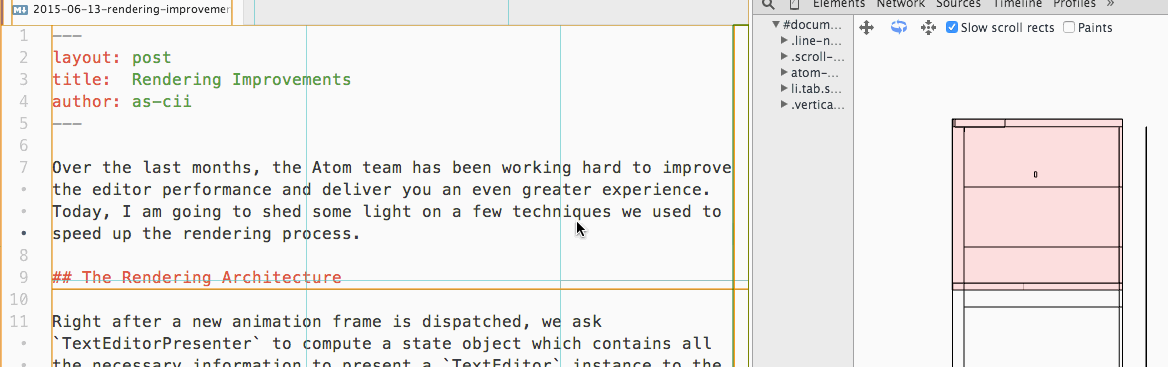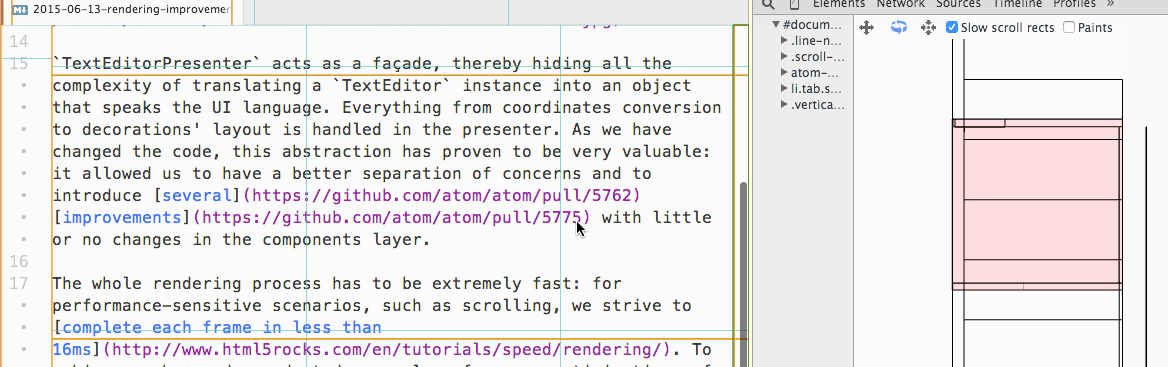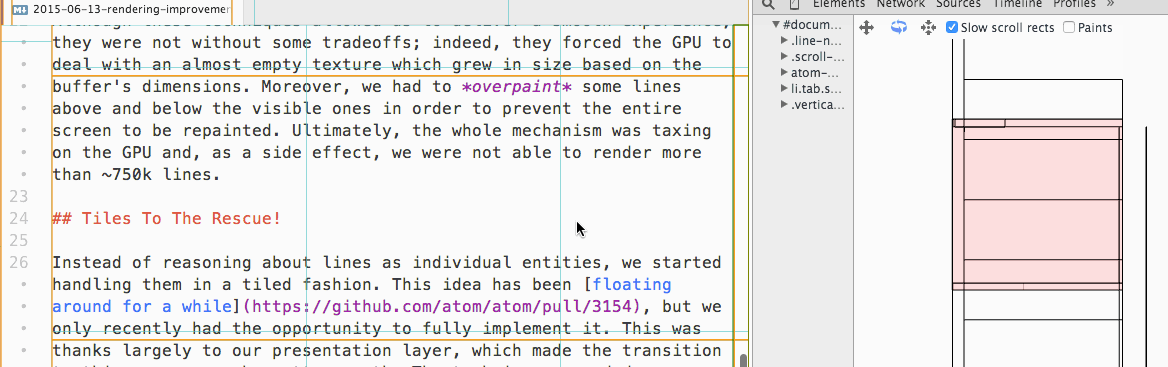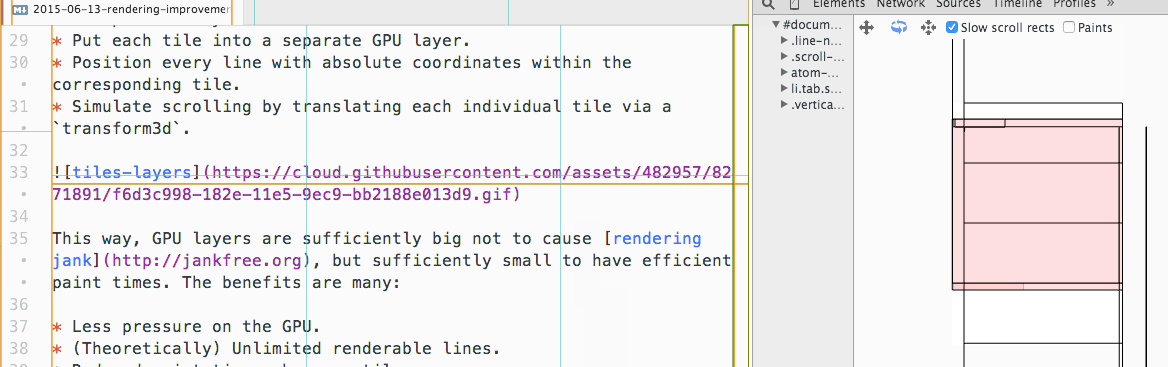
除了渲染导致的卡顿之外,因为 JavaScript 是单线程的,如果进行 CPU 密集的操作(例如在大量文件中进行正则搜索),也会阻塞事件循环,导致卡顿。就像普通的 Node.js 程序一样,如果希望进行 CPU 密集的计算,最好放到单独的进程而不是主进程,Atom 内建的搜索功能就是这样实现的:
scan = (regex, options={}, iterator) ->
deferred = Q.defer()
task = Task.once require.resolve('./scan-handler'), regex, options, ->
task.on 'scan:result-found', (result) ->
iterator(result)
deferred.promise
那么今天的主要内容就这么多了,接下来我想推荐几个我觉得非常好用的插件:
- git-plus 可以让你在命令面板中直接执行
git diff、git push 这样的命令。
- file-icons 可以给 tree-view 中的文件添加一个美观的图标。
- local-history 可以在你每次保存或编辑器失去焦点时在特定目录保存一份快照,以防万一。
- highlight-selected 可以像 Sublime Text 一样高亮当前文件中和你选择的单词一样的单词。
- linter 是一个语法风格检查的框架,如果你写 JavaScript 的话可以使用 linter-eslint 进行检查。
- 对于特定语言有一些专门的代码补全插件,例如 JavaScript 可以使用 atom-ternjs,TypeScript 可以使用 atom-typescript,React 可以使用 react。
Atom 本身是开源项目,也有着活跃的社区:
其他参考链接: