可以说 JavaScript 的生态来自于用户态类库的充分竞争,Deno 则在 Runtime API 之外提供了 Standard Library(类似 golang.org/x)、提供了全套的开发工具链(fmt、test、doc、lint、bundle),在试图提供开箱即用的使用体验的同时,也削弱了第三方生态。
Atom 是 GitHub 在 2014 年发布的一款基于 Web 技术构建的文本编辑器,我从 2014 年末开始使用 Atom 完成我的全部工作,对 Atom 很是喜爱,也创建了 Atom 的中文社区、翻译了一部分 Atom 的文档和博客。今天我将着重介绍 Atom 背后的故事,包括底层的 Electron、如何对 Atom 进行定制、Atom 的插件化机制、Atom 在启动速度和渲染性能方面的优化等。
GitHub 的联合创始人之一 Chris Wanstrath 自 2008 年便有一个想法,希望使用 Web 技术构建一个像 Emacs 一样赋予开发者充分定制的能力的编辑器。但当时他忙于他的主要工作 —— GitHub,所以 Atom 一度被搁置,直到 2011 年,GitHub 添加了一个使用 Ace 实现的在线编辑代码的功能,这重新点燃了 Chris Wanstrath 对 Atom 的热情,于是他开始在业余时间开发 Atom。在 2011 年末,Atom 成为了 GitHub 的正式项目,也有了一些全职的同事加入,最后在 2014 年初 Atom 正式发布了,并于 2015 年发布了 1.0 版本。
所以 Atom 有什么亮点呢,我总结了这样几点:
像 Sublime Text 一样开箱即用
像 Emacs 一样允许开发者充分地定制
基于 JavaScript 和 Web 技术构建
开源且拥有一个活跃的社区
虽然 Sublime Text 之类的编辑器已经足够好用了,第一天学习编程的新手也可以快速上手,但它们仅提供了非常有限的拓展性;而在另外一个极端,像 Vim 和 Emacs 这样的编辑器虽然赋予了开发者充分定制的能力,但却有着陡峭的学习曲线。虽然 Atom 的初衷可能并非如此,但 Atom 的确做到了兼顾易用性和可拓展性,在这两种极端中间找到了一个平衡。
就像 Java 开发者会使用基于 Java 构建的 Eclipse 或 IntelliJ IDEA、Clojure 开发者会使用基于 Lisp 的 Emacs 一样,作为 JavaScript 开发者我们也需要一款基于 JavaScript 和 Web 技术构建的编辑器。我觉得用自己熟悉的语言和技术去改造工具,并从工具的实现中得到启发这是很重要的一点,就像我后面介绍的那样,作为 Web 或 Node.js 开发者,我们都可以从了解 Atom 的设计和实现中受益。
Vim 和 Emacs 之所以能在过去几十年始终保持活力,很大程度上是因为只有「开源」才能构建一个持久的、具有生命力的社区。GitHub 当然也意识到了这一点,所以 Atom 同样是开源的,并且它现在已经有了一个活跃的社区。
Electron
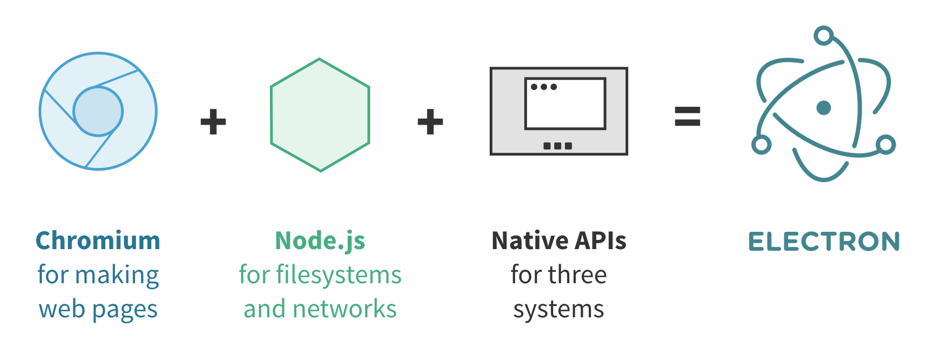
Atom 是基于 Electron,这是一个帮助开发者使用 Web 技术构建跨平台的桌面应用的工具,实际上 Electron 原本叫 Atom Shell,是专门为 Atom 设计的,后来才成为了一个独立的项目。Electron 将 Chromium 和 Node.js 结合到了一起:Chromium 提供了渲染页面和响应用户交互的能力,而 Node.js 提供了访问本地文件系统和网络的能力,也可以使用 NPM 上的几十万个第三方包。在此基础之上,Electron 还提供了 Mac、Windows、Linux 三个平台上的一些原生 API,例如全局快捷键、文件选择框、托盘图标和通知、剪贴板、菜单栏等等。
基于 Electron 的应用往往会有很大的体积,即使在打包压缩之后通常也有 40MiB,这是因为 Electron 捆绑了整个 Chromium 和 Node.js。但这也意味着你的应用运行在一个十分确定的环境下 —— 你总是可以使用最新版本 Chromium 和 Node.js 中的特性而不必顾及兼容性,这些新的特性往往会有更好的性能同时提高你的开发效率。
<body> <h1>Hello World!</h1> We are using node <script>document.write(process.versions.node)</script>, Chrome <script>document.write(process.versions.chrome)</script>, and Electron <script>document.write(process.versions.electron)</script>. </body>
可以看到,我们就像在使用 NPM 上一个普通的包一样在使用 Electron 来控制 Chromium 来创建窗口、加载页面,你也可以控制 Chromium 来进行截图、管理 Cookie 和 Session 等操作;同时在页面中我们也可以使用 process.versions 这样的 Node.js API,最后我们的 Hello World 看起来是这样的:
因此 Atom 提供了一个服务(Service)API,将被调用方抽象为服务的提供者,而将调用方抽象为服务的消费者,插件可以声明自己同时提供一个服务的几个版本,通过 Semantic Versioning(语义化版本号)表示,例如 status-bar 的 package.json 中有:
1 2 3 4 5 6 7 8 9
"providedServices":{ "status-bar":{ "description":"A container for indicators at the bottom of the workspace", "versions":{ "1.1.0":"provideStatusBar", "0.58.0":"legacyProvideStatusBar" } } }
let target = atom.views.getView(atom.workspace.getActiveTextEditor()) atom.commands.dispatch(target, 'markdown:paste-as-link')
从上面的代码中我们可以看到,atom.commands.dispatch 在执行一个命令时还需要指定一个 DOM 元素,结合前面注册命令和映射快捷键的例子,我们可以发现 Atom 中的快捷键和命令实际上都是被注册到一个 CSS 选择器上的。这是因为在 Atom 这样一个复杂的环境中,一个快捷键可能会被多次映射到不同的命令,例如下图,我在存在代码补全的选单的情况下按了一下 Tab 键:
我为 Atom 主界面中的各个可视组件画了一个示意图,Atom 中最核心的区域叫「窗格(Pane)」,窗格可以横向或纵向被切分为多个窗格,窗格中可以是自定义的 DOM 元素(例如右侧的设置界面),也可以是 TextEditor(当然其实这也是一个 DOM 元素)。在窗格构成的核心区域之外,插件可以从四个方向添加「面板(Panel)」来提供一些次要的功能,面板中包含的也是自定义的 DOM 元素。可以想象,上图中的那样一个界面,是在两个窗格的基础上,先从底部添加一个 find-and-replace 的面板,然后从左侧添加一个 tree-view 的面板,最后再从底部添加一个 status-bar 的面板。
Workspace 对应着 Atom 的一个窗口,TextEdtior 对应着窗格中的一个文本编辑区域,可以算是 Atom 较为核心的组件了,我们来看看它们的 API 文档:
Atom 非常善于通过「社会化」的方式维护社区,因为有了 timecop,终端用户也可以感知到导致启动缓慢的插件,并在 GitHub 上向作者反馈(Atom 要求所有插件的源代码必须托管在 GitHub)。在 Atom 1.0 发布时,有一些 API 的行为有调整,Atom 也是通过类似的方式向终端用户展示未迁移到最新的 API 的插件,督促作者来进行修改。
于是 Atom 借助 Electron 提供的 ASAR 归档格式,将整个 node_modules 和其他的代码文件打包成了一个单个的文件,这样 Atom 在启动时只需要读取这一个文件,省下了很多的时间。
优化渲染性能
在 Atom 的早期版本中,当你打开一个代码量较大的文件时,文本编辑区域就会出现卡顿。前面我们提到,Atom 的整个窗口其实就是一个网页,如果网页渲染速度达不到 60fps —— 也就是无法总是在 16 毫秒内完成一次渲染,就会出现人可以感受到的卡顿。所以我们下面介绍的渲染性能优化思路其实是适用于所有的 Web 应用的,只是很少有应用能够有着 Atom 这样复杂的页面。
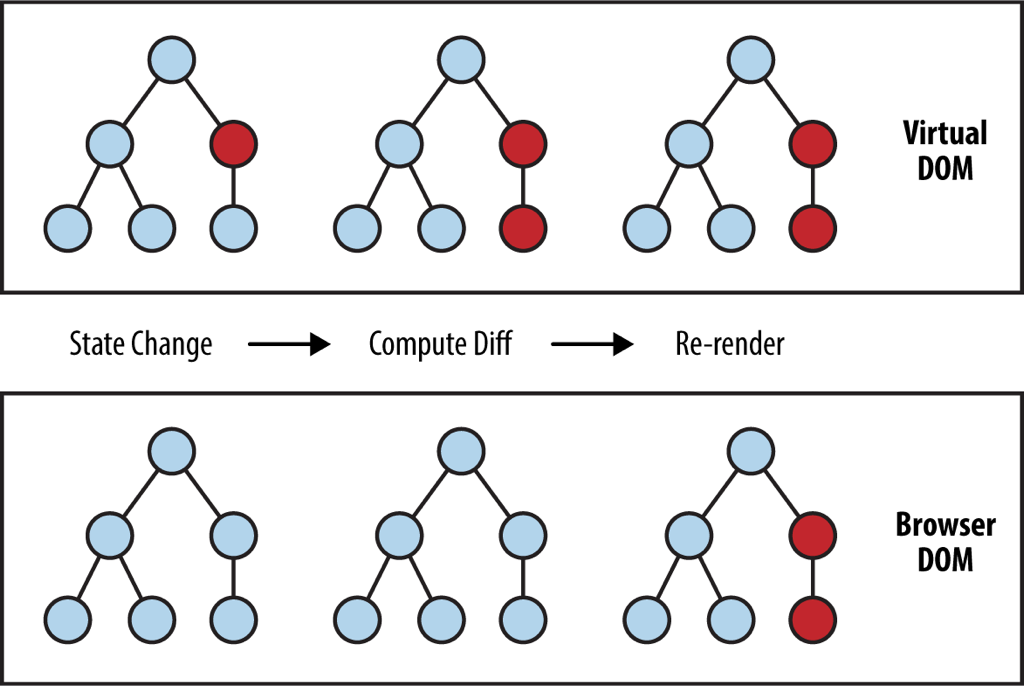
众所周知 JavaScript 是基于事件循环单线程地运行的,每当事件循环中的一个函数执行完成,如果它修改了 DOM,浏览器就会尝试进行重排和重绘来更新页面的显示,如果我们将对 DOM 的修改分散在事件循环中的多个函数中,就会多次触发不必要的重排和重绘,所以优化渲染性能有两个关键的思路:
避免直接地、频繁地、反复地操作 DOM
保持 DOM 树尽可能地小
为了将对 DOM 的操作集中到一起,我们有必要引入一个抽象层,也就是所谓的 Virtual DOM,我们总是在 Virtual DOM 上进行修改,而后再由 Virtual DOM 将我们的多次修改合并,一起更新到真正的 DOM 上。Atom 一开始使用了 React 所提供的 Virtual DOM,不过后来为了更细粒度的控制,切换到了一个自行实现的 Virtual DOM 上:
在采用了 Virtual DOM 之后也意味着插件不能够直接操作 Atom 的文本编辑区域的 DOM 了,为此 Atom 提供了 Marker 和 Decoration 这两个机制来允许插件间接地与文本编辑区域交互,Marker 和 Decoration 相当于是对 Virtual DOM 的进一步封装: